
The company’s event-based digital Neuromorphic IP can add efficient AI processing to SoCs.
Edge AI is becoming a thing. Instead of using just an embedded microprocessor in edge applications and sending the data to a cloud for AI processing, many edge companies are considering adding AI at the edge itself, and then communicating conclusions about what the edge processor is “seeing” instead of sending the raw sensory data such as an image. To date, this dynamic has been held back by the cost and power requirements of initial implementations. What customers are looking for is proven AI tech that can run under a watt, and that they can add to a microcontroller for on-board processing.
Many startups have entered the field, looking to compete in an area of AI which does not have an 800-pound incumbent to displace (a.k.a., NVIDIA). Many startups have some sort of in-memory or near-memory architecture to reduce data movement, coupled with digital multiply-accumulate (MAC) logic. BrainChip is taking a different approach, applying event-based digital neuromorphic logic with SRAM that the company says is power-efficient, flexible, scalable, and enables on-chip learning. Let’s take a closer look.
The Akida Platform
Brainchip has a lengthy list of enhancements it has engineered to the second-generation Akida platform. The motivation of these additions has been to enable processing on the modalities customers are increasingly demanding: real-time video, audio, and time-series data such as speech recognition, human action recognition, text translation, and video object detection. For some of these apps, the addition of an optional Vision Transformer (ViT) engine, along with an enhanced neural mesh can deliver up to 50 TOPS (Trillions of Operations Per Second) according to the company.
The company is selling its IP into designs for sensors and SoCs looking to add AI to the edge. While uptake has been slow for BrainChip’s first product, the AKD1000, there have been some high-profile demonstrations of its use by companies like Mercedes in the EQXX concept vehicle and by NASA on a project for autonomy and cognition in small satellites and adoption of their development kits and boards by a number of companies for prototyping purposes.
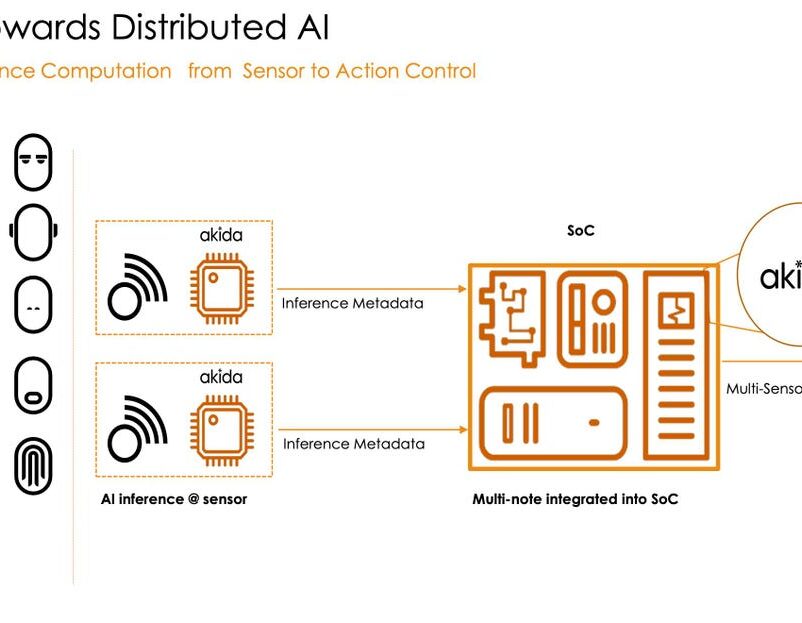
Now, with the second generation. BrainChip has added support for 8-bit weights and activations, the ViT mentioned above, and hardware support for an innovative Temporal Event-Based Neural Net (TENN) support. Akida maintains its ability to process multiple layers at a time, managed by its smart DMA which handles model and data load and store autonomously. This can enable low-power sensors attached to an Akida node without the need for CPU. The diagram below shows how Akida sensors can be coupled with an SoC for multi-sensor inference processing.
The Akida IP can be used to create sensors and be deployed within more advanced SoCs.
The new Akida platform, expected to be available later this year. is designed to process a variety of popular networks, including CNNs, DNNs, Vision Transformers, and SNNs. The event-based design is particularly good at time series data for problems such as audio processing, video object detection, and vital sign monitoring and prediction.
BrainChip has shown some initial benchmarks that demonstrate orders of magnitude fewer operations and smaller model size which can benefit edge AI implementations. In video object detection, a 16m implementation can handle 30FPS at 1382×512 resolution, in under 75mW. Keyword detection in 28nm can support over 125 inferences/sec taking less than 2 microJoules per inference. BrainChip has applied for patents in TENN model acceleration.
The Akida processor and software can implement multi-pass processing as well as on-chip learning.
Akida’s runtime software manages the operation efficiently including key features like its multi-pass processing which are handled transparent to the user. Model development and tuning is supported on the TensorFlow framework with MetaTF.
The Akida Architecture and associated Benefits.
BrainChip envisions three ranges of adoption, including a basic MCU with 1-4 nodes for always-on CPU-less operation, a MCU+Deep Learning Accelerators class, and a high-end MCU with up to 64 nodes and an optional ViT processor. In all cases, on-chip learning is possible by leveraging the trained model as a feature extractor and adding new classes in the final layer while untethered from cloud training resources.
Akida can provide power efficient AI alternatives across a broad range of solutions that currently … [+]
Conclusions
While BrainChip has been vocal in the past about the partnerships it has forged, such as with MegaChips and Renesas, commercial growth has been slower, possibly a function of the IP model taking longer to ramp. With the inclusion of 8-bit operations, the Vision Transformer, temporal convolutions (TENN models), and the ability to run models like ResNet-50 completely on the Akida Neural processor with minimal CPU dependencies, we believe the company is laying the foundation to turn the corner and land some bigger design wins. A key factor may be the software, which is currently TensorFlow based but will soon support PyTorch as well, an essential addition given the current development landscape.
Disclosures: This article expresses the opinions of the authors, and is not to be taken as advice to purchase from nor invest in the companies mentioned. Cambrian AI Research is fortunate to have many, if not most, semiconductor firms as our clients, including Blaize, Cerebras, D-Matrix, Esperanto, FuriosaAI, Graphcore, GML, IBM, Intel, Mythic, NVIDIA, Qualcomm Technologies, Si-Five, SiMa.ai, Synopsys, and Tenstorrent. We have no investment positions in any of the companies mentioned in this article and do not plan to initiate any in the near future. For more information, please visit our website at https://cambrian-AI.com.


